
《科创板日报》4月21日讯(编辑宋子乔)在AI大模型竞赛中,Meta选择重押视觉模型,继推出零样本分割一切的SAM后,扎克伯格亲自官宣了重量级开源项目DINOv2。
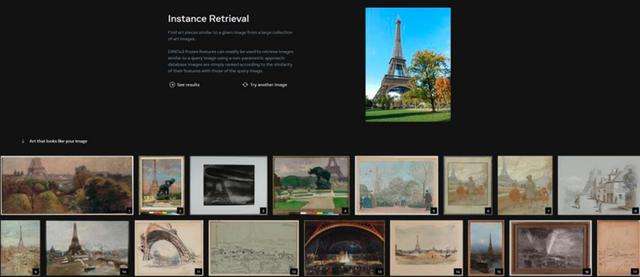
据介绍,DINOv2是计算机视觉领域的预训练大模型,模型参数量是10亿级,采用Transformer架构,能在语义分割、图像检索和深度估计等方面实现自监督训练,不需微调即可用于多种下游任务,可以被用于改善医学成像、粮食作物生长、地图绘制等。

DINOv2有何亮点?
主要体现在两方面——DINOv2可以为大语言模型提供丰富的图像特征,有助于完善多模态GPT应用;其蒸馏成小模型后效果依然优秀,便于在各种边缘场景及本地化落地。
对于前者,Meta已表示计划将DINOv2集成到更大、更复杂的AI系统中,作为视觉主干提供丰富的图像特征与大型语言模型进行交互。
国盛证券分析师刘高畅表示,DINOv2能比用图像文本对做训练的模型得到更丰富的图像特征,这将让整个系统能更好地理解图像,对多模态AI的发展起到加速作用。
值得注意的是,多模态技术还能助力游戏内容与元宇宙构造,随着AR/VR技术的发展,未来将能构建逼真的虚拟现实。扎克伯格就强调,DINOv2可以极大地加持元宇宙的建设,让用户在元宇宙中的沉浸体验更出色。
上述分析师大胆预测,1-5年内,随着多模态的发展带来AI泛化能力提升,通用视觉、通用机械臂、通用物流搬运机器人、行业服务机器人、真正的智能家居会进入生活。未来5-10年内,结合复杂多模态方案的大模型有望具备完备的与世界交互的能力,在通用机器人、虚拟现实等领域得到应用。
对于边缘场景落地,简单来说是指将大模型移植到移动端或是算力有限的场景。
运行大型的模型需要强大的硬件,这可能会限制模型在C端场景的应用,为大模型“瘦身”成了手机等移动终端运行大模型的前提,其技术路径多样,包括通过剪枝让模型稀疏化、知识蒸馏对模型进行压缩、通过权重共享来减少参数量等。
DINOv2即采用模型蒸馏的方式,将大型模型的知识压缩为较小的模型,从而降低推理时的硬件要求。据官方介绍,Meta开源了多个不同参数规模的预训练模型,在相同的规模下比较,DINOv2在多种测试基准的得分都能优于目前开源视觉模型中表现最好的OpenCLIP。
Meta之外,高通、华为等科技巨头也在致力于实现AI大模型在终端的轻量化部署,谷歌、腾讯、百度等已将模型压缩技术紧密结合移动端模型部署框架/工具。
https://baijiahao.baidu.com/s?id=1763760011300790294&wfr=spider&for=pc
© 版权声明
文章版权归作者所有,未经允许请勿转载。